

🤵♀️ 3.5% rule, “Augplacement” i macierz Task Risk/Complexity
🤵♀️ 3.5% rule, “Augplacement” i macierz Task Risk/Complexity
6 notatek, wykresów i konceptów.

Drodzy,
Znów odłożyło mi się trochę nieopierzonych konceptów, które zebrałem w notatkowe szwarc, mydło i powidło.
🤵♀️ 1. Macierz Task Risk/Complexity w Customer Experience
💪 2. Augmentation, Replacement vs. “Augplacement”?
🪧 3. “3.5% rule” i fenomonelogia skutecznego protestu
🗣️️️️ 4. Notatki z wywiadu z Aravind Srinivas, CEO Perplexity
💡 5. Technika Feynmana, czyli błąd “założenia bezzałożeniowości” i myślenia addytywnego
🤖 6. Paradoks cyfrowego pośrednika
Czas potrzebny na przeczytanie: 8 min 05 sekund.
🤵♀️ 1. Macierz Task Risk/Complexity w Customer Experience
Ostatnio Jared Sleeper podzielił się ciekawym wykresem "AI for CX Efficient Frontiers", który plasuje różne zadania związane z doświadczeniem klienta (CX) na dwóch osiach: Y - Complexity (złożoność) i X - Risk (ryzyko) ze wskazaniem na potencjał automatyzacji.

Kilka obserwacji i przemyśleń:
Simple i Low Risk. To typowy no-brainer do automatyzacji, gdzie mała złożoność zadań idzie w parze z niskim ryzykiem jeśli coś pójdzie nie tak (FAQ → jeśli nie znajdę odpowiedzi zwracam się do customer support).
Zanim odrzucimy ten obszar jako fruit hanging too low zaryzykowałbym tezę, że tu jest najwięcej obszarów do zrobienia dla masowego rynku i firm, które nie słyszały o RAGach, Claude, Perplexity. To drobne rozwiązania pod solopreneurship i małe SaaSy i wrappery na OpenAI.Simple i High Risk. To taka “dolina Moraveca” od sformułowanego przez niego paradoksu, że obliczeniowy koszt funkcji poznawczych i przetwarzanie podstawowych bodźców sensorycznych jest często bardziej energochłonny niż abstrakcyjne myślenie.
Innymi słowy: jazda na rowerze dla dziesięciolatka jest banalnym zadaniem, nie dla maszyny. Przemnożenie miliardowych macierzy w jest niewykonalne dla człowieka, dla maszyny to 1 sekunda. Podobnie tutaj: skasowanie danych użytkownika to jedno kliknięcie, ale złożoność tego zadania zasadza się przede wszystkim na ryzyku i sieci konsekwencji i zależności biznesowych, gdzie potrzebna jest koordynacja.Koncentracja na osi X ryzyka? Pisałem ostatnio o measurability vs. personal interest matrix, czyli jak kluczowe w sprzedaży do korporacji jest mierzalność rozwiązania i niwelowanie ryzyka (“nobody was fired for hiring IBM”). W wszystkich AI-owych rozwiązaniach/automatyzacjach poruszałbym się więc po tej osi: “czy automatyzacja tego zadania oprócz kompleksowości zredukuje ukryty koszt ryzyka?”. To nie musi być eliminacja ryzka, ale np. wzięcie go na siebie (księgowość, kancelaria prawna).
💪 2. Augmentation, Replacement vs. “Augplacement”?
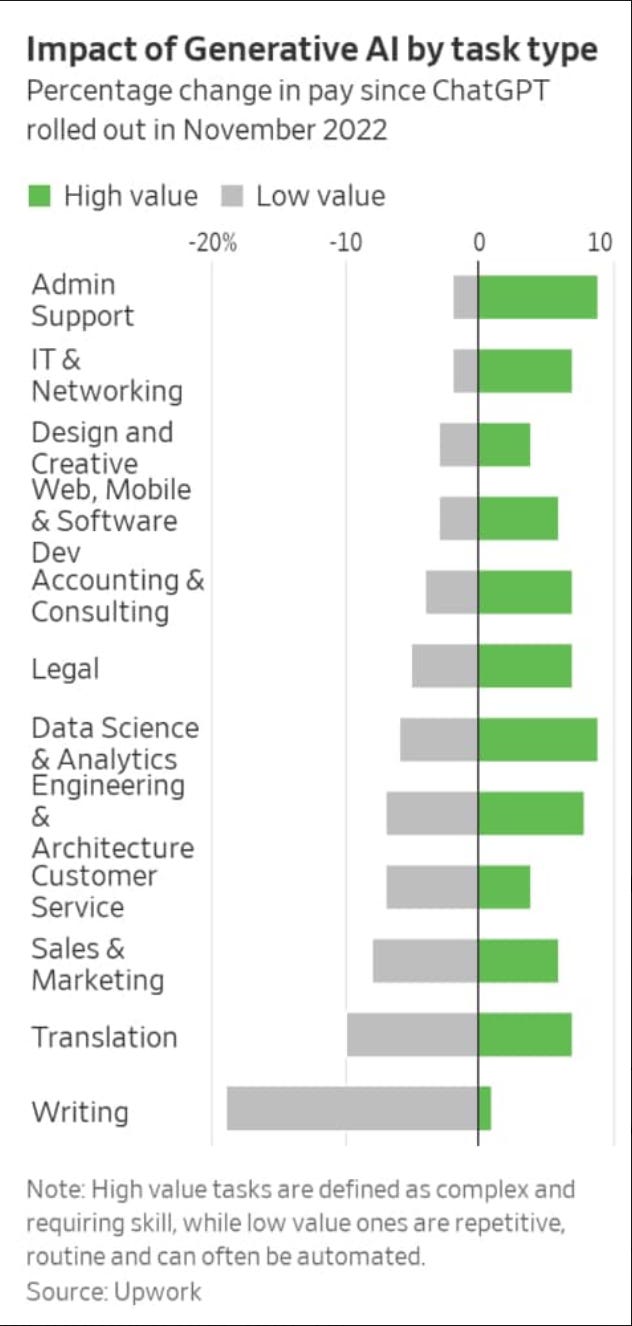
W nawiązaniu do powyższego nasunęło mi się też kilka przemyśleń w kontekście wykresu, którym podzielił się Michał Kreczmar na Facebooku, pokazującym procentową zmianę wynagrodzeń dla różnych kategorii pracy od momentu wprowadzenia ChatGPT w listopadzie 2022 roku.
Raczej nie ma tu zaskoczenia, że role związane z tłumaczeniem czy copywritingiem nie zyskały, choć tu kilka caveats:
Upwork głównie obsługuje freelancerów, co oznacza, że wyniki mogą nie odzwierciedlać sytuacji na tradycyjnym rynku pracy.
Czynniki sezonowe + makro: Niektóre kategorie zadań mogą podlegać sezonowym wahaniom popytu w połączeniu ze spowolnieniem w IT w 2023.
Ciekawsza jest relacja miedzy “Customer service” a “Admin support”.
Premia wynagrodzeń w administracji (+10%) może wynikać z tego, że szereg zadań mógł ulec automatyzacji eksponując ten “high-risk” aspekt, który obejmuje ludzki osąd, podejmowanie decyzji, zarządzanie interesariuszami, “wypełnianie szczelin” korporacyjnej tkanki zależności i powiązań (“przy tej dyrektorce nie wspominamy o rozwodzie”).
Słowem: zadania w wsparciu administracyjnym często obejmują mieszankę rutynowych i niestandardowych czynności, wymagających osądu, priorytetyzacji i koordynacji - AI wspomaga te funkcje, zwiększając wartość roli ludzkiej (odciążenie z rutyny, augmentacja w roli ludzkiej).
W przypadku client service z kolei może to bardziej zastępowanie (replacement), niż wsparcie (augmentation).
Customer service z kolei to często one-time interaction, gdy administracja to rozciągnięty w czasie internal client multi-interaction, który czasem wymaga większego “okna kontekstowego”.
…ale to wszystko spore uproszczenie w duchu Klarna zastąpiła chatbotem 700 stanowisk w customer support (pamiętajmy, że w planie jest IPO więc taki “efficiency-grooming” dla inwestorów jest na porządku dziennym). Osobiście myślę, że w obliczu proliferacji AI i automatyzacji paradoksalnie premię zarobkową zgarnie customer support, który może będzie ewoluował w taką rolę administracji.
Tak, w pierwszej fali zredukuje liczbę miejsc pracy, doprowadzi do optymalizacji (jak Klarna), bo wiele rutynowych obszarów da się pewnie załatwić spięciem RAG + FAQ + czatbot, ale w miarę przejęcia tych rutynowych zadań “drabina eskalacyjna” do białkowego customer supportu skróci się i dotyczyć będzie już przypadków wymagających dużej decyzyjności.
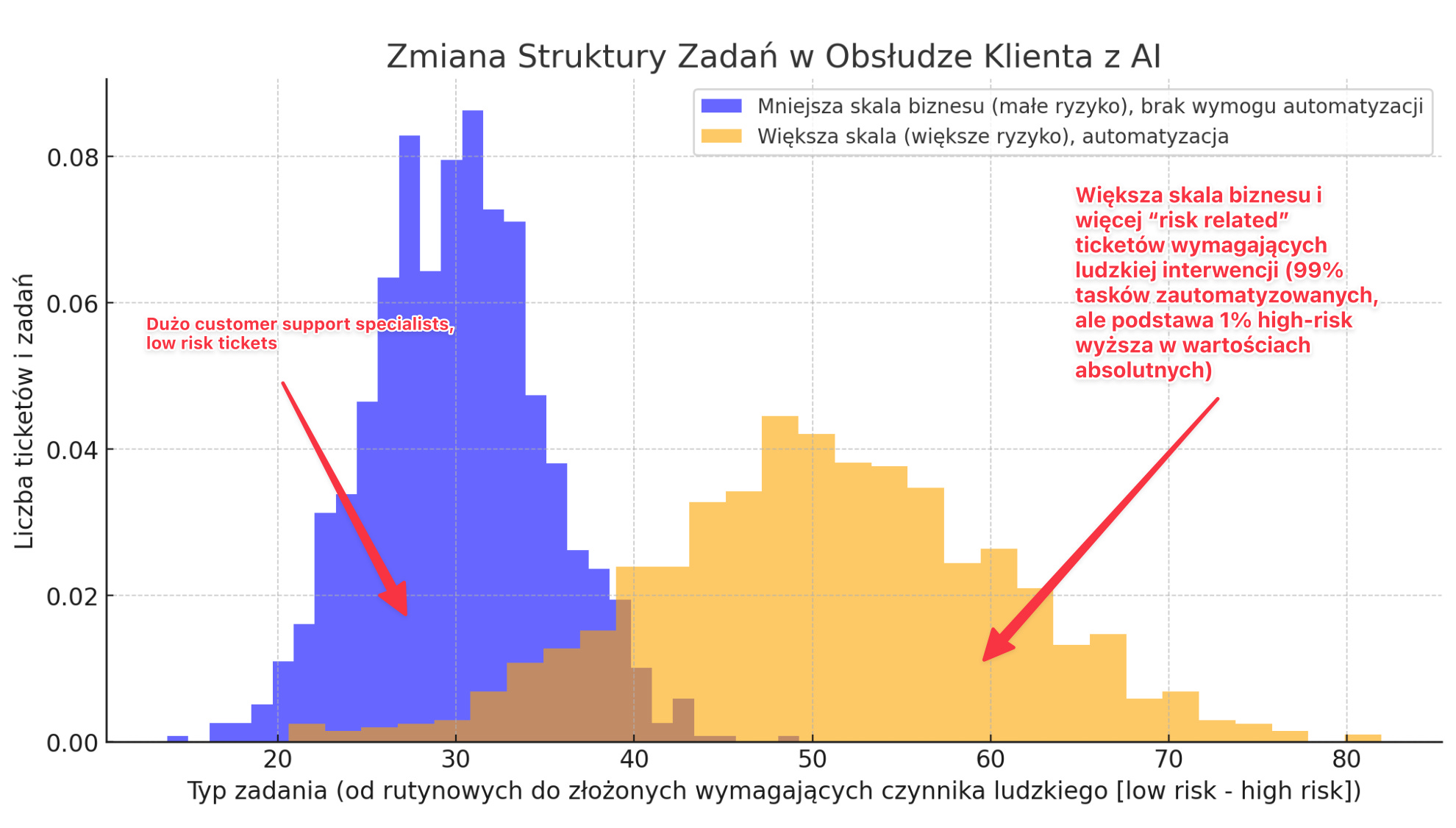
“Augplacement”? Obsługa klienta może będzie już wymagała nie “operatora ticketów” (“musimy spytać dział prawny, dział X, dział Y”) a Managera / Customer Service Ops ze znajomością szerszego kontekstu biznesowego ("czy możemy przepuścić tę transakcję uwzględniając ryzyko, ale też kwartalny cel departamentu X, Y, Z?", "niby zgodne z literą prawa, ale czy z duchem prawa i niepisanym kodeksem etycznym firmy?").
Myślę, że to się naturalnie już dzieje, natomiast daleki jestem od ogłaszania śmierci customer supportu szczególnie, że wraz ze skalą biznesów rośnie ryzyko: wycięcie feature’a z którego korzysta 1% bazy w aplikacji z 200 mln użytkowników to usunięcie populacji Łotwy, 2 mld to już 20 milionowa Rumunia. Więc szczególnie przetwarzanie płatności (jak Klarna) i biznesy high-risk wraz ze skalą mogą automatyzować więcej powtarzalnych obszarów dla 99% userów, ale będą wymagać więcej tych do obsługi 1% (np. frauds).
🪧 3. “3.5% rule” i fenomonelogia skutecznego protestu
Liczba protestów na świecie wzrosła ponad trzykrotnie między 2006 a 2020 rokiem. Większość protestów dotyczyła reżimów politycznych, niesprawiedliwości, praw obywatelskich, nierówności oraz zmian klimatycznych, o czym traktuje ostatnio opublikowany w Nature artykuł The science of protests: how to shape public opinion and swing votes.

Kilka obserwacji i hipotez:
Przełom ekonomiczny 2014? Do 2014 roku największa liczba protestów była związana z problemami ekonomicznymi, po 2014 zaczęły się koncentrować na politycznej reprezentacji i prawach obywatelskich. Pierwsza hipoteza to “mam już zapewniony byt, chciałbym praw”, ale druga to polaryzacja (inwazja Rosji w 2014 i wybór Trumpa w 2016 poprzedzony ingerencją Rosjan).
Trzy czynniki wpływające na skuteczność protestów:
Duże protesty są bardziej skuteczne niż małe.
Protesty bez przemocy są skuteczniejsze niż te z użyciem przemocy (ale z czasem skuteczność spada).
Represje ze strony władz mogą zwiększyć wsparcie dla protestujących.
Reguła 3,5%. Według badań, każde ruchy, które zmobilizowały co najmniej 3,5% populacji, odniosły sukces. Jednak liczba ta może być myląca, gdyż większa liczba osób może wspierać ruch bez aktywnego udziału w protestach.
Efekt deszczu. Efekt deszczu odnosi się do metody badawczej, która wykorzystuje przypadkowość opadów deszczu jako sposób na analizę wpływu protestów na określone rezultaty, takie jak zachowania wyborcze. Ponieważ deszcz zmniejsza liczbę uczestników protestów, można porównać wyniki w regionach, gdzie padało, z tymi, gdzie nie padało, aby zidentyfikować wpływ protestów na dane zjawisko.
Wyniki pokazały, że mniej deszczu sprzyjało w 2020 protestom, które były głównie pokojowe, a te przyczyniły się do wzrostu udziału głosów Demokratów w wyborach prezydenckich w listopadzie 2020 roku o +1.2-1.8%.
Hipoteza: organizuj protesty w pogodne dni, w rejonach, gdzie nie pada, warunki pogodowe są korzystne.
Inna sprawa to udane demokratyczne przewroty (1946-2020) i tu już nie jest tak wesoło:
od końca II wojny światowej doszło do 550 zamachów stanu (200 z nich udanych)
liczba przewrotów maleje (więcej ugruntowanych demokracji? ugruntowane dyktatury nie do ruszenia? brak wpływu innych państw, bo brak interesu w ingerencji lub "da się dogadać"?)
więcej przewrotów "z deszczu pod rynne": w latach 60-tych tylko 26% zamachów stanu kończyło się nową dyktaturą, po 2010 ta liczba wzrosła do 50%

🗣️️️️ 4. Notatki z wywiadu z Aravind Srinivas, CEO Perplexity
Nie słucham dużo podcastów, więc pewnie wysłuchanie jednego to już świeto, z którego próbuję jak najwięcej wyciągnąć. Lex Fridman to chyba obecnie jeden z najpopularniejszych, więc spisałem sobie kilka moich subiektywnych obserwacji, które skatalizował wywiad z CEO Perplexity.
Po raz n-ty jak wiele różnic może zdziałać UX/UI. “It’s very hard to make a real difference in just making a better(…) search engine than Google, because they have basically nailed this game for like 20 years. The disruption comes from rethinking the whole UI itself. Why do we need links to be occupying the prominent real estate of the search engine UI? Flip that”. Tu moja krótka naliza never bet against Google i UX ich API.
Plus Perplexity nie chce wygrać lepszym modelem (korzysta z open source’owych modeli) co pokazuje, że pogardzane “wrappery na OpenAI” wciąż są dobrym rozwiązaniem, bo secret sauce może sprowadzać się do tych 10% (nisza, use case, UX/UI etc.).
Make the weakness of your enemy a strength + your margin is my opportunity.
“Why did Amazon build like the cloud business before Google did? Even though Google had the greatest distributed systems engineers ever, like Jeff Dean and Sanjay, and built the whole map produce thing, server racks, because cloud was a lower margin business than advertising. There’s literally no reason to go chase something lower margin instead of expanding whatever high margin business you already have. Whereas for Amazon, it’s the flip”“(…) Alphabet, makes money from so many other things. Just because the ad model is under risk doesn’t mean the company’s under risk. For example, Sundar announced that Google Cloud and YouTube together are on a $100 billion annual recurring rate right now. That alone should qualify Google as a trillion-dollar company if you use a 10X multiplier and all that.”
Hustler, Hacker, Hipster, Dropouts —> powrót do łask Academics & PhDs ? Narracja przez ostatnie 15 lat była mocno naznaczona gloryfikacją dropouts i entrepreneurial hackers w opozycji do skostniałego systemu edukacji (“rzuć studia, buduj”, “MBA? You got to build not study!”, Thiel Fellowship etc.), natomiast mam wrażenie, że cały dyskurs wokół AI prowadzi do ciekawej bifurkacji:
VC → Solopreneurship (bits)? Do zbudowania aplikacji-wrappera do OpenAI nie trzeba już być VC-backed, musimy się pogodzić, że to nie jest “science”, a “engineering”, w czym nie ma nic złego. Tę ścieżkę myślę, że coraz mocniej będą wypełniać solopreneurs.
Rise of academics (atoms). Do przełomowych technologii (tego osławionego deep tech) potrzebna będzie głęboka wiedza domenowa i może powrót do łask akademików? Do tego etosu zdaje się być bliżej Aravindowi:
“So I think that’s why I admire those guys. They had deep academic grounding, very different from the other founders who are more like undergraduate dropouts trying to do a company. Steve Jobs, Bill Gates, Zuckerberg, they all fit in that mold. Larry and Sergey were the ones who were like Stanford PhDs trying to have this academic roots and yet trying to build a product that people use.”
Ciekawy screenshot growth hack oparty na próżności.
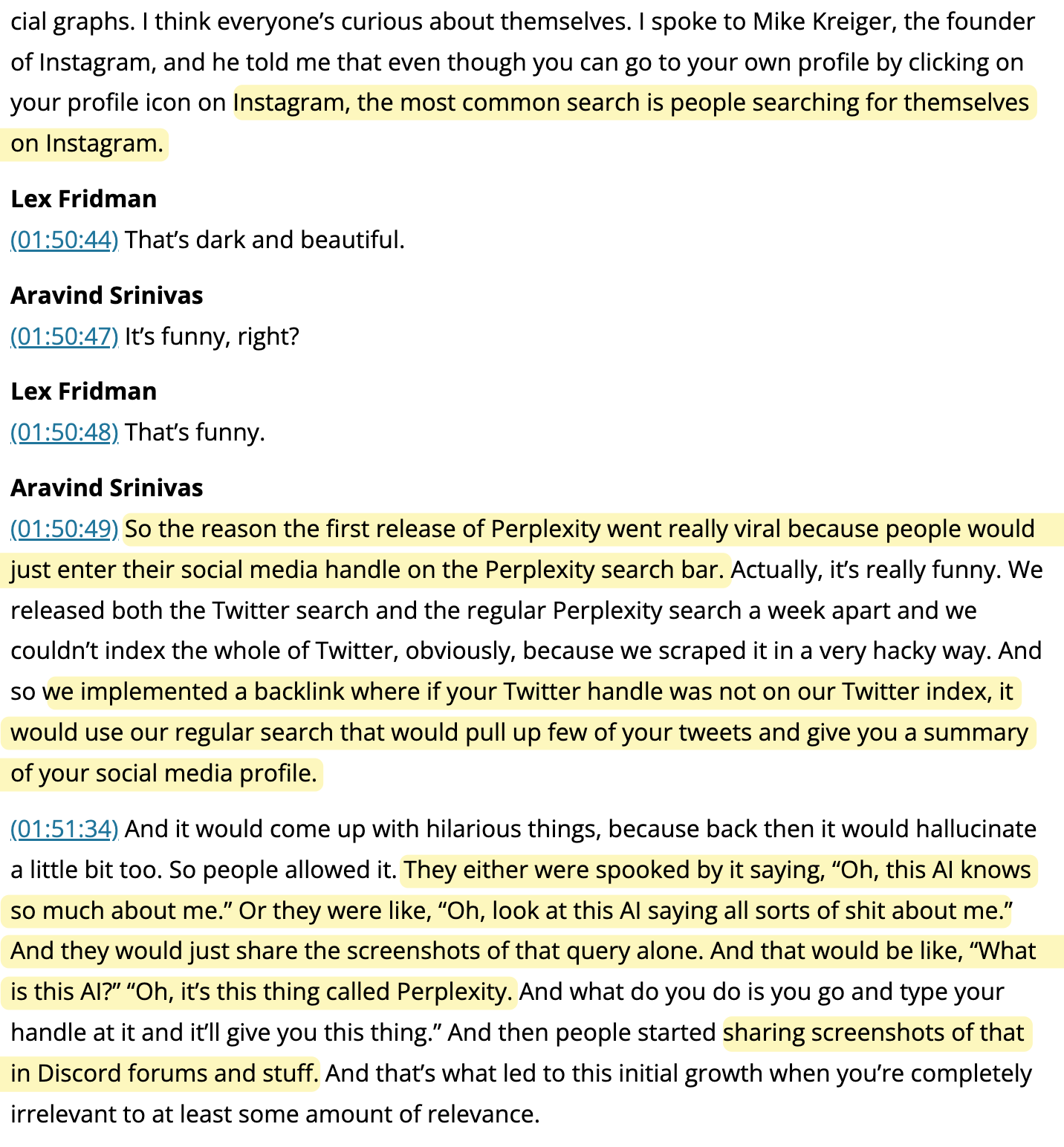
Nie wiem czy polecam odsłuchać cały podcast, ale na pewno znajdzie się tam kilka ciekawych fragmentów.
💡 5. Technika Feynmana, czyli błąd “założenia bezzałożeniowości” i myślenia addytywnego
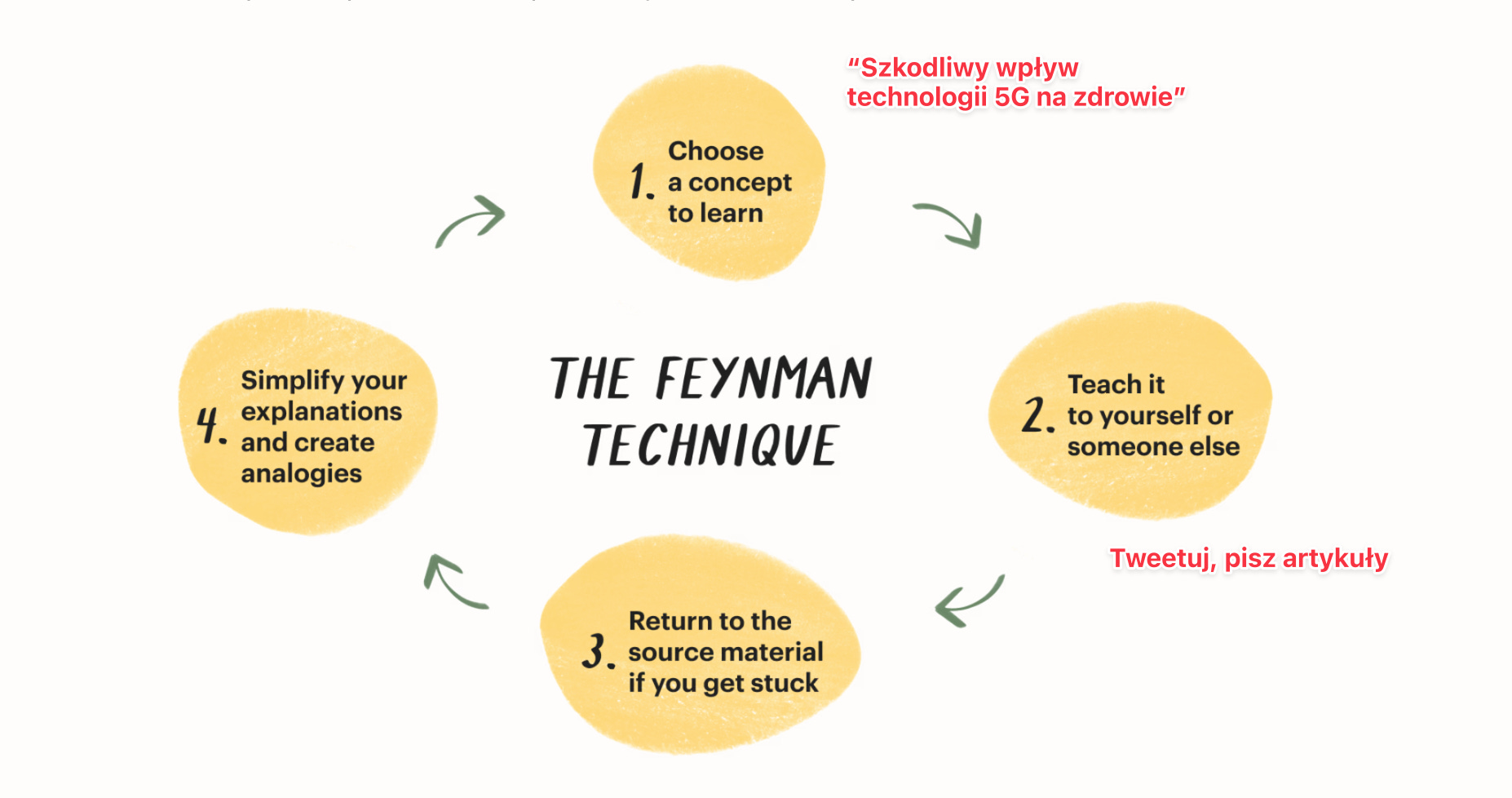
Podawana często dalej przez twitterowych thinkboiów “Technika Feynmana” uchodzi za narzędzie eliminacji luk w wiedzy, ale mam wrażenie, że jej kluczowy problem tkwi w podskórnym błędzie “założenia bezzałożeniowości”, który czerpiemy z fizykalizmu (“świat jest matematyczny, fizyka to jedyna prawdziwa nauka” etc). Wybór tematu do nauki, pozornie neutralny, jest też zawsze naznaczony wcześniejszymi przekonaniami uczącego się.
Przykład: wyobraźmy sobie zwolennika teorii spiskowych, który stosuje tę technikę, by zgłębiać "szkodliwość technologii 5G na zdrowie". Ironia sytuacji polega na tym, że cały proces uczenia się jest skazany na porażkę, bo a) wybór tematu opiera się na fałszywych przesłankach b) technika ta, zamiast prowadzić do prawdy ma charakter addytywny tzn. produkuje wiedzę, dodaje ją, umacnia błędne przekonania, przekształcając je w spójne, ale fałszywe twierdzenia.
Fascynacja tego typu techniką bardziej obnaża nasze prekoncepcje dotyczące nauki i wiedzy:
Mit nauki wolnej od założeń. Tak jak badania antyszczepionkowców bardziej wynikać mogą z ideologii wolnościowej niż z pobudek naukowych (mimo że ubrane w szaty wyższości poznawczej) tak naiwnością jest ignorować fakt, że każde badanie, nawet najbardziej obiektywne, nosi ślady kulturowych i osobistych kontekstów badaczy.
Odkrywanie, budowanie czy wypełnianie luk? Idealistyczne założenie, że nauka jest czystą, obiektywną eksploracją prawdy, jest dobrze stosowalne do utartych obszarów wiedzy (nabywania wiedzy, która jest już ugruntowana np. “historia I Wojny Światowej, czego jeszcze nie wiem?”), ale staje się problematyczne w obszarach mniej zbadanych. To ciekawie problematyzuje jak odmienne pojawiają się stosunki do kwestii poznania: odkrywamy wiedzę (“odkrywanie tego co już jest, ale jest ukryte”), budujemy (to pewnie bliższe Foucault i że normatywne reguły nauki są arbitralnie np. co jest zdrowe, “naturalne”, a co nie) czy raczej wypełniamy luki?
Ta mania gromadzenia wiedzy przewija się obecnie w szeregu artefaktów kulturowych od “52 books challenge” przez “Disappear for 6 months” i zdaje się hołdowąć jakiejś mieszance tezauryzatorsko-indywidualistycznego fantazmatu gdzieś w gąszczu “do your own research” (indywidualizm poznawczy), “change your life” (jednostkowa sprawczość) i “learn and improve” (akumulacja).
Temat na osobną porcję notatek, tu natomiast zakończę, że nieraz chcąc być latarnią w mroku niewiedzy, staniemy się kolejną iskrą w płomieniach dezinformacji.
🤖 6. Paradoks cyfrowego pośrednika
Bardzo ciekawa obserwacja i wątek, jaki poruszył Michał Jaskólski w kontekście działania autonomicznych agentów i ich “statusu ontologiczno-prawnego”.
Czy AI agent działający w moim imieniu jest scrapperem czy przedłużeniem mojej jednostkowej woli?
Klasyczne, czy w przypadku błędów lub naruszeń praw, kto jest odpowiedzialny – agent AI, jego twórca, czy użytkownik? (Agent AI działa w imieniu użytkownika, ale jego decyzje mogą nie zawsze odzwierciedlać intencje użytkownika)

Miłej niedzieli,
Kamil Stanuch
PS. Jak oceniasz dzisiejszy mail? Zostaw komentarz lub “❤️”, jeśli podobał Ci się artykuł - zawsze cenię komentarze i insighty od Was, a daje to też lepszą pozycję w sieci Substack. Możesz też anonimowo dać ocenę poniżej - krytyczne oceny są dla mnie bardzo ważne i pozwalają mi poprawić warsztat.
Ciekawie przedstawiona Technika Feynmana! Czy to jednak nie jest tak, że to tylko technika/narzędzie? Dopiero wykorzystanie jej w konkretnym kontekście lub z konkretnych pobudek będzie powodowało, że jest dobra lub zła?
Bardzo fajnie napisane